Parametric polymorphic--or driving behavior with data
At Software Development Best Practices 2005 I attended as many design and architecture talks as I could fit in. I enjoyed H.S. Lahman’s talk on Invariants and Parametricpolymorphicm. His talk illustrated how instead of abusing inheritance, you can use data to drive general algorithms. This is something I’ve done on many an occasions, and no, I don’t think it violates responsibility-driven design principles. In fact, it is a vital technique for creating extensible designs where extensions can be done externally to your application (by business people creating appropriate data).
An example is worth illustrating the concept. Consider the problem of calculating charges for a water and sewage bill (my first COBOL program as an analyst/programmer for the city of Vancouver, WA made these calculations). Although there were many, many different types of customers (industrial, commercial, residential of various sorts, government, non-profit, etc.), the basic algorithm for computing the customer’s bill was to apply a minimum charge based on the customer type and meter size, then apply a rate stepping function: Base rate + (first tier rate * units in first tier) + (2nd tier rate * units in second tier). Sewage was another similar calculation. Searching the internet, I was happy to find a published similar example of water and sewage rates for the city of Shreveport, Louisiana.
The key to making a single calculation work for a variety of different computations is inventing an encoding for a business rule or algorithm or policy (your invariant) that can be driven by descriptive data that can be treated uniformly by a single algorithm. This data can be encapsulated in a specification object. Of course, given a myriad of Rates and Tier values, these would most likely be encoded in a relational database or some tabular scheme that would be objectified into a specification object.
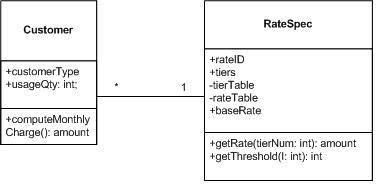
Computing monthly charges is pretty simple (ignoring floating point arithmetic precision for the sake of simplicity).
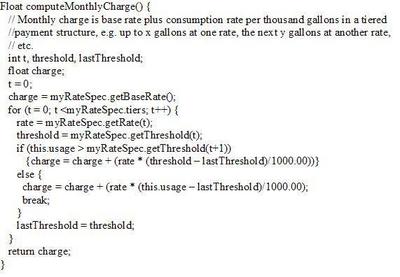
Parametric polymorphism is a fancy name for using parameterized data to drive behavior. A bad alternative would be to create many classes of objects to accomplish the same thing. Imagine the nightmare of maintaining a different class for each type of rate and threshold combination! Fact is, though, there is a lot of rate information to maintain. No getting around that. Rather than being hardwired into a program, the rate and threshold specs can be maintained by non-programmers. Even better.
More generically, decision tables can represent information compactly that can be used to drive complex computations. Drools.org offers open source frameworks that support integrating decision tables with Java. If you’ve tried these on a project, I’d be interested in hearing about your experiences.
The key is to effectively exploit objects and data to drive flexible, scalable solutions. If you have really quirky computations and rules that can’t be tamed and codified in a simple manner, you can still exploit these techniques. But you will likely have to untangle and codify several decisions in order to drive several different computations. No one said life is easy. But effectively encoding decisions and variations is key to building flexible, scalable solutions that don’t have to be solved by bruteforce, ugly, rigid code.