Design (Un)Certainty and Decision Trees
Billy Vaughn Koen, in The Discussion of The Method: Conducting the Engineer’s Approach to Problem Solving, says, “the absolute value of a heuristic is not established by conflict, but depends upon its usefulness in a specific context.”
Heuristics often compete and conflict with each other. Frequently I use examples I find in presentations or blog posts to illustrate this point.
For example, I took this photo of a presentation by Michiel Overeem at DDD Europe where he surveyed various approaches people employed to update event stores and their event schemas.

Five different alternatives for updating event stores[/caption] Event stores are often used (not exclusively) in event-sourced architectures, where instead of storing data in traditional databases, changes to application state are stored as a sequence of events in event stores. For an introduction to event sourced architectures see Martin Fowler's article. An event store is comprised of a collection of uniquely identified event streams which contain collections of events. Events are typed, uniquely identified and contain a set of attribute/value pairs.
Michiel found five different ways designers addressed schema updates, each with different tradeoffs and constraints. The numbers across the top of the slide indicate the number of times each approached was used across 24 different people surveyed. Several used more than one approach (if you add up the x/24 count at the top of the slide there are more than 24 updates). Simply because you successfully updated your event store using one approach doesn’t mean you must do it the same way the next time. It is up to us as designers to sort things out and decide what to do next based on the current context. The nature of the schema change, the amount of data to be updated, the sensitivity of that data, and the amount of traffic that runs through apps that use the data all play into deciding which approach or approaches to take.
The “Weak schema” approach allows for additional data to be passed in an event record. The “upcaster” approach transforms incoming event data into the new format. The “copy transform” approach makes a copy and then updates that copy. Michiel found that these were the most common. “Versioned events” and “In-Place” updates were infrequently applied.
I always want to know more about what drives designers to choose a particular heuristic over another. So I was happy to read the research paper Michiel and colleagues wrote for SANER 2017(the International Conference on Software Analysis, Evolution and Reengineering) appropriately titled The Dark Side of Event Sourcing: Managing Data Conversion. Their paper, which gives a fuller treatment of options for updating event stores and their data schemas, can be found here. In the paper they characterized updates as being either basic (simple) or complex. Updates could be made to events, event streams, or the event store itself.
Basic event updates included adding or deleting an attribute, or changing the name or value of an attribute. Complex event updates included merging or splitting attributes.
Basic stream update operations were adding, deleting, or renaming events. Complex Stream updates involved merging or splitting events, or moving attributes between events.
Basic store updates were adding, deleting or renaming a stream. Complex store updates were merging and splitting streams or moving an event from one stream to another.
An example of a simple event update might be deleting a discountCode attribute. An example of a complex event update might be splitting an address attribute into various subparts (street, number, etc.).
Importantly, their paper offered a decision framework for selecting an appropriate update strategy which walks through a set of decisions leading to approaches for updating the data, the applications that use that data, or both. I’ve recreated the decision tree they used to summarize their framework below:
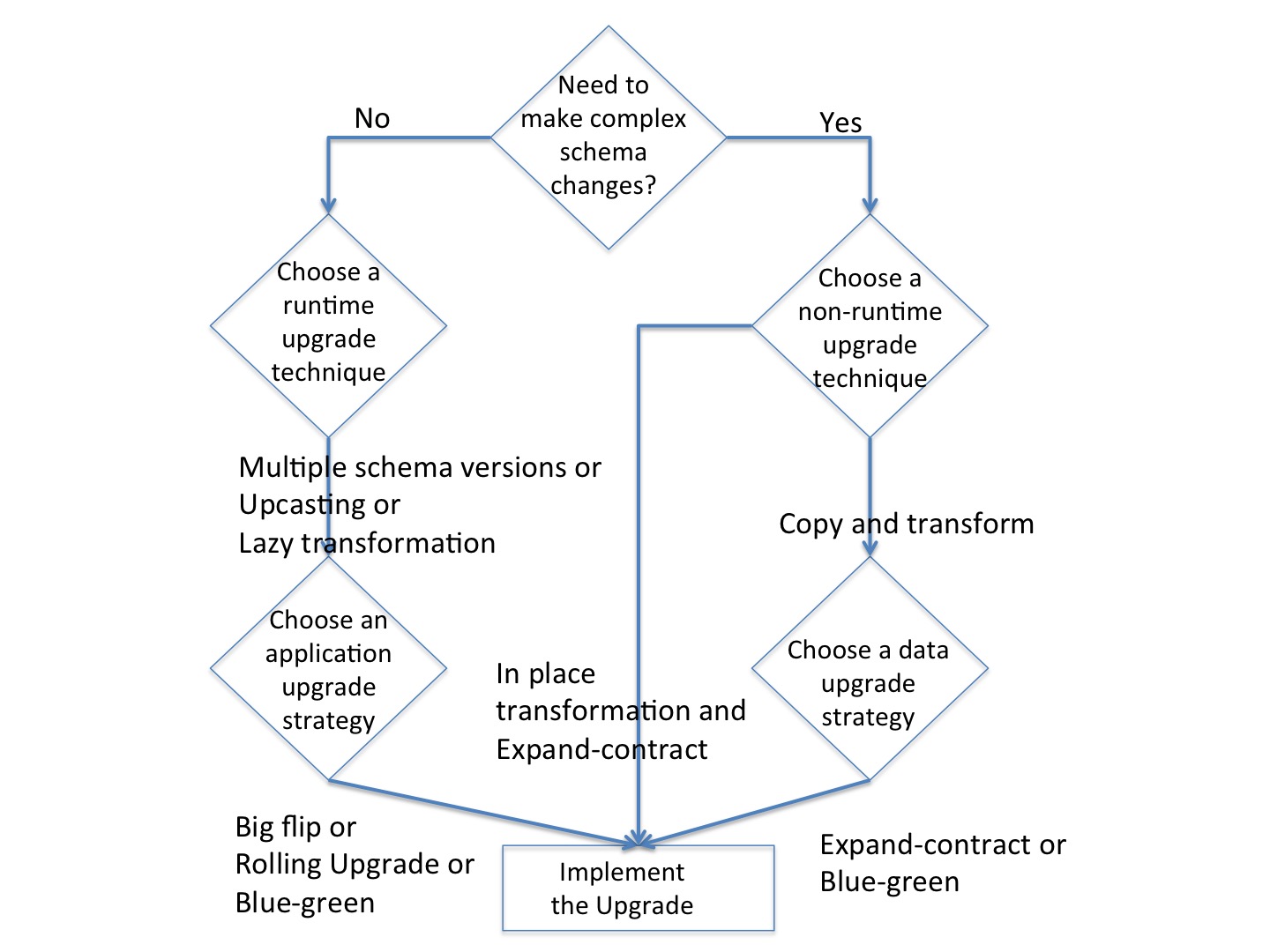
The authors also tested out their decision framework with three experts. Those experts noted that in their experiences they found complex schema updates to be rare. Hmm, does that mean that half of the decision tree isn’t very useful?
Also, they offered that instead of updating event schema they could instead use compensating techniques to accomplish similar results. For example, they might write code to create a new projection used by queries which contained an event attribute split into subparts—no need to update the event itself. Should the left half of their decision tree be expanded to include other compensating techniques (such as rewriting projection code logic)? Perhaps.
Also, the experts preferred copy or in-place transformations instead of approaches that involved writing and maintaining lots of conversion code. I wonder, did they do this even in the case of “basic” updates. If so, what led them to make this decision?
Decision trees are a good way to capture design options. But they can also be deceptive about their coverage of the problem/solution space. A decision table is considered balanced or complete if it includes every possible combination of input variables. We programmers are used to writing precise, balanced decision structures in our code based on a complete set of parameters. But the “variables” that go into deciding what event schema update approach aren’t so well-defined.
To me, initially this decision framework seemed comprehensive. But on further reflection, I believe it could benefit from reflecting the heuristics used by more designers and maintainers of production event-sourced systems. While this framework was a good first cut, the decision tree for schema updates needs more details (and rework) to capture more factors that go into schema update design. I don’t know of an easy way to capture these heuristics except through interviews, conversations, and observing what people actually do (rather than what they say they prefer).
For example, none of the experts preferred event record versioning, and yet, if it were done carefully, maybe event versions would require less maintenance. Is there ever a good time for “converting” an old event version to a newer one? And, if you need to delete an attribute on an event because it is no longer available or relevant, what are the implications of deprecating, rather than deleting it? Should it always be the event consumers’ responsibility to infer values for missing (deleted) attributes? Or is it ever advantageous to create and pass along default values for deleted attributes?
This led me to consider the myriad heuristics that go into making any data schema change (not just for event records): Under what conditions is it better to do a quick, cheap, easy to implement update to a schema—for example deciding to pack on additional attributes, having a policy to never delete any?
People in the database world have written much about gritty schema update approaches. While event stores are a relatively new technology, heuristics for data migration are not. But in order to benefit from these insights, we need to reach back in time and recover and repurpose these heuristics from those technologies to event stores.Those who build production event sourced architectures have likely done this or else they’ve had to learn some practical data schema evolution heuristics through experience (and trial and error). As Billy Vaughn Koen states, “If this context changes, the heuristic may become uninteresting and disappear from view awaiting, perhaps, a change of fortune in the future.” He wasn’t talking about software architecture and design heuristics per se, but he could have been.